







Aim:
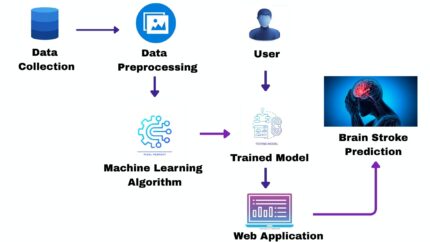
The aim of this study is to develop a privacy-preserving and personalized driver stress monitoring system using a Tree-Based Personalized Clustered Federated Learning (TPCFL) approach, which effectively addresses the challenges of non-IID physiological data by grouping drivers based on similarities in their data characteristics, optimizing cluster selection, and enabling accurate stress detection for both existing and new unlabeled drivers without compromising sensitive information.
Introduction:
Recent advancements in wearable biosensors have enabled continuous and accurate collection of physiological signals, offering new possibilities for driver stress monitoring. However, such sensitive data raises privacy concerns and often exhibits non-independent and identically distributed (non-IID) characteristics, reducing model performance in traditional federated learning (FL) approaches. This study proposes a Tree-Based Personalized Clustered Federated Learning (TPCFL) method that clusters drivers based on similarities in their physiological data, optimizes model selection through a hierarchical structure, and balances personalization with generalization. The approach preserves privacy, addresses non-IID challenges, and supports stress prediction for both existing and new unlabeled drivers with high accuracy.
Proposed system:
The proposed system introduces a Tree-Based Personalized Clustered Federated Learning (TPCFL) framework for accurate, privacy-preserving driver stress monitoring using physiological data from wearable sensors. Unlike traditional FL approaches that train a single global model, TPCFL tackles the challenge of non-IID data by clustering drivers based on similarities in their personal physiological data characteristics using hierarchical agglomerative clustering (HAC). A hierarchical “granularity tree” is constructed, where each cluster is trained with its own FL model, ranging from general at the root to highly personalized at the leaves. An optimized cluster selection process identifies the most suitable model for each driver, balancing personalization with generalization to improve prediction accuracy. This design also enables integration of new drivers without labeled data by matching them to the closest existing cluster using similarity measures, thus avoiding retraining from scratch. The system preserves privacy by keeping raw data local while only transmitting model updates and feature distributions to a central server. Experiments on benchmark datasets (MIT Drivedb and AffectiveRoad) demonstrate superior accuracy compared to standard FL and clustered FL, making TPCFL highly effective for real-world applications in driver safety, health monitoring, and intelligent transportation systems.









Reviews
There are no reviews yet.